


“Debunking the 2023 hike in the Social Cost of Carbon”, by Ross McKitrick, by curryja
“I have a new paper out in the journal Nature Scientific Reports in which I re-examine some empirical work regarding agricultural yield changes under CO2-induced climate warming.”



← Unraveling the Narrative Supporting a Green Energy Transition
Debunking the 2023 hike in the Social Cost of Carbon
Posted on February 21, 2025 by curryja | Leave a comment
by Ross McKitrick
I have a new paper out in the journal Nature Scientific Reports in which I re-examine some empirical work regarding agricultural yield changes under CO2-induced climate warming. An influential 2017 study had argued that warming would cause large losses in agricultural outputs on a global scale, and this played a large role in an upward revision to the Biden Administration’s Social Cost of Carbon (SCC) estimate, which drives regulatory decision in US climate rulemaking. I show that a lot of data had been left out of the statistical modeling, and once it is included there was no evidence of yield losses even out to 5 C warming.
Background
In 2023 a team of economists working for the Biden Administration concluded the SCC needed to be increased by a considerable amount. The higher the SCC, the costlier the regulatory burden that can be justified by the agency. This not only affected US regulations but Canada’s as well since our own environment ministry adopted the new US values when justifying a sweeping set of new greenhouse gas regulations. I wrote an op-ed about the SCC change in May 2023 in which I drew attention to the important role played by a revision to projected agricultural yield damages. While it is difficult to trace where, precisely, all the changes came from, I estimate about $50 of an approximately $100 increase in the 2030 value of the SCC (holding the discount rate constant) was attributable to the revised agricultural yield damage estimates.
These revisions were attributed to estimates of crop yield losses from a 2017 paper published in Nature Communications by Frances Moore et al. called “New science of climate change impacts on agriculture implies higher social cost of carbon.” I’ll call that paper M17. I was familiar with this paper because Kevin Dayaratna and I had studied it while preparing a response to a comment by Philip Meyer on a paper of ours on the SCC. I knew, for instance, that M17 used a data set originally developed for a 2014 paper published in Nature Climate Change by Andy Challinor et al. called “A meta-analysis of crop yield under climate change and adaptation.” I’ll refer to that one as C14. But C14 and M17 had different implications about the impact of CO2-induced warming on crop yields. In the C14 model CO2 fertilization offsets the damage from warming, whereas in M17 the combined effect is negative for most crops across most warming paths. So why the difference?
It was not possible to tell simply by reading the papers. Neither one provided a detailed explanation of its regression analysis. M17, in particular, did not report its regression results nor was its model directly comparable to C14. So in 2023 I decided to get the data and try to replicate both sets of findings. While both papers said the data was available online at a website called
http://www.ag-impacts.org
no such site currently exists, and the Wayback machine entries did not include any data. I emailed Moore to ask for her data, but she was at that time working for the Biden Administration and her university email was inactive. I then reached out to Challinor who replied promptly and sent me his data set.
The C14 Dataset
The data was a compilation of results from many crop yield simulations done by other authors around the world. The file was an Excel spreadsheet with 1,722 rows each containing numerous variables drawn from the underlying studies including the crop type, study location, change in CO2 level (dC), change in temperature (dT), change in precipitation (dP), change in yield (dY), whether adaptation was included, and various other details. It was immediately apparent that many of the dC entries were missing. In fact only half of the data set appeared usable for regression modeling, which Challinor confirmed had been the case. It was a straightforward matter to replicate the Challinor results since they were based on a simple linear regression. The number of usable data rows in the version I received was slightly different from that reported in C14 and my replication was not exact, but it was close enough.
The M17 regression model was much more ornate than C14 since they included all possible cross-product terms plus some additional temperature data Moore’s coauthor Tom Hertel sent me. My coefficient estimates were similar to those reported in M17 but again not exact. I then used the M17 regression results to construct yield projections by crop type. I was able to compare my estimates to some unpublished calculations sent to me by Moore after she had finished her secondment in Washington. My replications were again not exact but pretty close so I was satisfied I was on the right track.
Many of the differences between M17 and C14 came down to different choices in setting up the regression equation. C14 allowed the CO2 fertilization effect to be linear as concentrations rose, whereas M17 imposed diminishing returns. In one version of my analysis I employed a flexible regression model that allowed the data to determine the response and it turned out to be close to linear, supporting the C14 version. But a referee later objected to my approach and while I didn’t agree with the objections I removed that discussion since it wasn’t necessary for the paper’s main point. M17 also restricted the role of adaptation so that if no climate change happened (dC = dT = 0) adaptation alone could not boost yields. This was a reasonable assumption to impose since the model is attempting to track climate change-induced yield responses.
But I was also curious about all those missing dC entries. I started checking the underlying source papers and found that in many cases either the number was available or could be recovered by consulting the documentation for the climate scenario being simulated. I recovered 360 missing dC entries which allowed me to do the regressions on a much larger data set. And that made a very large difference.
Reanalysis on the Expanded Dataset
In the following figure, showing yield changes versus warming for four crop types, the original data set is called “C14”. On the expanded data set (“All”) the regression coefficients changed such that the yield simulations net of CO2fertilization showed no output losses, even out to 5 C warming.
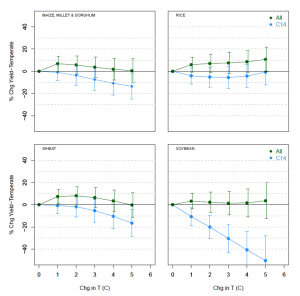
Even without doing the economic modeling I could therefore conclude that the M17 analysis did not justify any revision to the SCC estimate (except perhaps downwards).
I wrote up the results and submitted them to the journal in which C14 had been published: Nature Climate Change. This was about a year ago (end of February 2024). NCC declined even to review the paper, telling me “we are not persuaded that your findings will be of sufficiently immediate interest to the broader climate change community”. And I totally agree—I think my findings will be of no interest at all to the climate change community, since they don’t advance the cause! NCC suggested I submit my paper instead to Nature Scientific Reportswhich I did.
NSR had the paper reviewed and in early June I was told it was rejected. The reviewers argued that my equation connecting dC to dT was wrong and that my empirical analysis depended on choosing two key parameter values (baseline CO2 and climate sensitivity) but if I varied these slightly my overall results would fall apart. However, while there was a typo in my dC-dT equation it didn’t carry over to the code, and it was easy to show (since I submitted my data and code) that my results were invariant to the proposed parameter changes. So I decided to write the editor contesting the decision. A managing editor contacted me and said there is a formal appeal process and explained how to use it, but also cautioned me that it typically takes a long time to process an appeal request and they are rarely accepted. Nonetheless on a Friday in June I submitted all the documents. On Monday morning I was told my appeal had been accepted, and I was advised to submit a revised version of the manuscript, which I did right away.
I then waited a long time. In October I queried the journal and was told they were reaching out to new reviewers but so far had not received any responses. I queried again in December and was told they had found new reviewers but had not received the reviews. But in early January the new reviews came through and they were supportive. The requested revisions were mainly editorial but the analysis and conclusions were upheld. From that point on publication was routine.
Whither the SCC?
Of course the topic has now been rendered somewhat moot by the Trump Administration’s January 20 Executive Order suspending the SCC on the grounds that it is “marked by logical deficiencies, a poor basis in empirical science, politicization, and the absence of a foundation in legislation.” The EPA has until mid-March to issue guidance on how to address these problems including possibly scrapping the use of the SCC altogether. I have had no contact with people working on that undertaking but if any of them were to ask me I would tell them the following.
Measuring the SCC is not a scientific procedure akin to measuring the weight of an atom or the speed of light. The SCC is based on so-called Integrated Assessment Models (IAMs) that contain countless assumptions and yield complicated “if-then” statements. If the following assumptions are true, then a ton of CO2 emissions will cause $X worth of damage to the world. Whoever gets to pick the “If” statements determines what the “then” statement will be. And you can pick studies that guarantee any SCC value you like, although some are more plausible than others. Ultimately the SCC is determined by the political and social process of choosing who gets to write the report. The Biden-era SCC report was written by people whose antennae were up for any reasons whatsoever to boost the SCC estimate, and who ignored evidence pointing in the other direction. The report even warns the reader that they probably overlooked many reasons why the SCC is even higher than they have estimated because surely there are many other damages associated with CO2 that they have not yet thought of. (They claimed to have taken account of the benefits associated with CO2 fertilization in one of their two IAMs, but they did so based on the M17 analysis. Which means, in effect, they didn’t take it into account.)
From an economic perspective, the dirty little secret of climate policy is that CO2emission reductions are so costly, even if the US government accepted the Biden SCC estimate very few climate policies would survive a cost-benefit test, and if the SCC were lowered to something more reasonable none of them would. So in that sense climate activists will get no joy from hanging onto the SCC.
But beyond the question of what the magic SCC number should be, the bigger question is how you convince a bureaucracy not to rig the report-writing process. The 2013 Interagency Working Group SCC report boasted of consulting 11 separate government agencies, and the 2023 report additionally boasted of input from the National Academies of Science and outside expert reviewers. Yawn. The more agencies involved the less scrutiny a report gets. It is all but certain that no one checked any underlying data or undertook any replication work. And I know from experience in the IPCC and other bureaucratic processes that review comments going against a chapter author’s biases are ignored or argued away, while comments confirming an author’s biases are welcomed at face value. The scientific establishment has resisted all attempts to fix climate assessment processes because they always got to pick the authors. But now a very different team is going to do the picking. If the establishment grandees suddenly decide they don’t like the process, they should have said something sooner.
